Design Do’s
Understanding Access Patterns
- Design your schema based on how the application will query the data.
- Define all read and write operations before creating tables.
Partition Keys & Sort Keys
-
Use high-cardinality partition keys for even data distribution.

-
Use sort keys to query items within a partition in a specific order or range.
Secondary Indexes
- Use GSIs for additional access patterns requiring different partition or sort keys.
- Use LSIs to query by a different sort key while sharing the same partition key.
Denormalize Data
- Store related data together in the same item or partition to reduce query complexity.
Design for Query Efficiency
- Use composite keys to support range queries (e.g., filtering by date).
- Fetch only required attributes using projection expressions.
Use Composite Keys for Complex Queries
- Combine attributes into a single partition or sort key to support complex queries.
Model Many-to-Many Relationships
- Use a single table with composite keys for efficient queries between entities (e.g., users and orders).
Optimize for Write Throughput
- Ensure partition keys distribute writes evenly.
- Use write sharding for high write volumes on specific partitions.
Plan for Capacity and Scaling
- Use On-Demand Capacity Mode for unpredictable workloads.
- Use Provisioned Capacity Mode with Auto Scaling for predictable workloads.
Use Batch Operations
- Use
BatchGetItemandBatchWriteItemfor efficient bulk reads and writes.
Embrace Event-Driven Design
- Use DynamoDB Streams for real-time data propagation to other systems.
TTL for Expiring Data
- Use TTL attributes to automatically delete expired items.
Design Don’ts
Avoid Relational Database Design
- Don’t normalize data or create separate tables for every entity.
Avoid Poor Partition Keys
- Don’t use low-cardinality partition keys (e.g.,
Country) that lead to hot partitions.
Avoid Overusing GSIs
- GSIs incur additional costs; only use them when necessary.
Avoid Wide Partitions
- Don’t allow a single partition to hold >10 GB of data, especially with LSIs.
Avoid Projecting Unnecessary Attributes
- Only project required attributes into GSIs or LSIs to reduce storage and improve performance.
Avoid Storing Large Attributes
- Don’t store attributes >400 KB; use S3 for large objects and store references in DynamoDB.
Avoid Scans Without Indexes
- Don’t query without partition keys or indexes to avoid costly scans.
Don’t Ignore Size Limits
- Item size: 400 KB max.
- Partition Key: 2048 bytes max.
- Sort Key: 1024 bytes max.
- LSI Partition Limit: 10 GB per partition key.
Don’t Ignore TTL
- Use TTL to reduce storage costs by expiring unused data.
Avoid Overusing Strong Consistency
- Use strong consistency only when required as it doubles read costs.
Don’t Ignore Costs
- Optimize schema to minimize storage, read/write capacity, and replication costs.
Query Do’s
Filter Results Using Sort Keys
- Use conditions like
begins_with,between, or comparison operators to narrow query results.
Paginate Results
- Retrieve large datasets in chunks using pagination.
- Use
LastEvaluatedKeyto continue querying beyond 1 MB of data.
Enable Query Metrics
- Monitor query performance using CloudWatch and DynamoDB metrics.
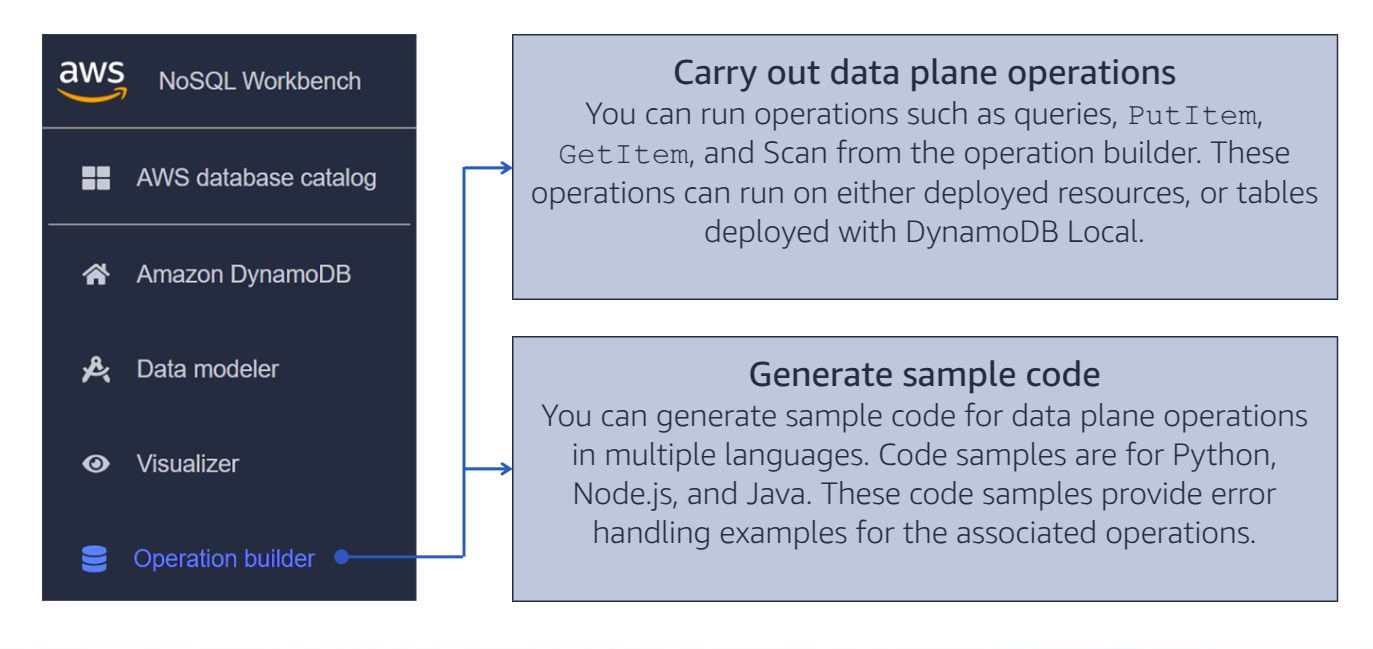
Test with NoSQL Workbench
- Simulate and test query efficiency and correctness using Amazon DynamoDB NoSQL Workbench.
Query Don’ts
Avoid Scans
- Don’t use Scan operations unless retrieving all items in the table is necessary.
Don’t Fetch Unnecessary Attributes
- Avoid fetching all attributes when only a subset is needed.
Don’t Hardcode Pagination Logic
- Handle
LastEvaluatedKeydynamically for flexible and complete data retrieval.
Indexes: Design & Pricing
Indexes in DynamoDB are critical for designing efficient access patterns. They let you query your table with attributes other than the primary key (PK and SK). Here’s a breakdown of indexes, their design considerations, and how pricing works:
1. Types of Indexes in DynamoDB
a. Local Secondary Index (LSI)
- Definition: Allows querying on an alternate Sort Key (SK) for the same Partition Key (PK) as the base table.
- Key Attributes:
- Same Partition Key (PK) as the main table.
- A different Sort Key (SK).
- Use Case: When you need alternate ways to sort or filter data for a given
PK. - Limits:
- Can only be created at the time of table creation.
- Maximum of 5 LSIs per table.
- Cannot exceed 10 GB of storage per partition.
Advantages:
- No extra storage cost (data is kept in the same partition as the main table).
- Queries are faster because LSIs share the same storage partitions.
Disadvantages:
- Limited to 5 LSIs.
- Rigid: You can’t add LSIs after table creation.
b. Global Secondary Index (GSI)
- Definition: Allows querying with a completely different Partition Key (PK) and/or Sort Key (SK) from the base table.
- Key Attributes:
- Independent PK and SK.
- Data is replicated into a new table (managed internally by DynamoDB).
- Use Case: When you need to query the table with attributes other than the base table’s keys.
- Limits:
- Maximum of 20 GSIs per table.
- Can be added after table creation.
Advantages:
- Very flexible, supports diverse access patterns.
- Can be added or modified after table creation.
Disadvantages:
- Extra storage cost: GSIs replicate indexed attributes and any projected attributes.
- Increased write costs: Every write to the main table also updates the GSI.
2. Designing Indexes
To design indexes effectively:
- Identify Access Patterns:
- Start with clear access patterns (e.g., query by tenant, list members by added epoch).
- Each access pattern may need a dedicated index.
- Minimize Attributes in Indexes:
- Use projection types to control which attributes are copied to the index:
- Keys Only: Only the PK and SK are included.
- Include: Specific attributes you specify.
- All: All attributes (most expensive).
- Use projection types to control which attributes are copied to the index:
- Avoid Over-Indexing:
- Only create GSIs or LSIs that are essential. Each index adds to costs and complexity.
- Use Composite Keys:
- Combine multiple attributes in your PK or SK to optimize queries
3. Pricing for Indexes
DynamoDB charges separately for:
- Read/Write Operations on Indexes:
- Each GSI has its own read capacity units (RCUs) and write capacity units (WCUs).
- Writes to the base table result in additional writes to all GSIs, doubling or tripling the write costs.
- Storage Costs:
- Data replicated to GSIs incurs storage costs.
- LSIs do not have additional storage costs because they share the same partitions as the base table.
How Pricing Works:
Write Capacity Units (WCU):
- 1 WCU is required for each write to the base table.
- For GSIs:
- If you have 1 GSI, every write to the base table requires an additional write to the GSI.
- Write costs increase linearly with the number of GSIs.
Read Capacity Units (RCU):
- 1 RCU is needed to read 4 KB of data from a GSI.
- Queries on GSIs are billed independently of the base table.
Storage Costs:
- $0.25 per GB per month for the base table.
- GSIs store indexed and projected attributes, so they add to the total storage cost.
4. Example: Cost Implications of GSIs
Let’s assume:
- Base Table: 100 writes per second, 1 KB items.
- 1 GSI: Indexed attributes replicate 1 KB per item.
Costs:
- Base Table Write Cost:
- 100 writes × 1 KB = 100 WCUs.
- GSI Write Cost:
- 100 writes × 1 KB = 100 WCUs.
- Total Write Cost:
- 200 WCUs (base table + GSI).
- Storage Cost:
- If 10 GB of data is replicated to the GSI:
- Base Table: $2.50/month (10 GB × $0.25).
- GSI: $2.50/month (10 GB × $0.25).
- If 10 GB of data is replicated to the GSI:
5. Key Considerations
- LSI vs. GSI:
- Use LSIs if alternate sort orders are needed within the same PK.
- Use GSIs for flexible queries with new PKs or SKs.
- Cost Management:
- Limit the number of GSIs.
- Use on-demand capacity mode for unpredictable workloads.
- Optimize attributes in the index with projection types.
Designing for DynamoDB
Key Concepts
- Design Schema Based on Query Patterns:
- Begin schema design with a clear understanding of the app’s specific query patterns.
- Minimize Table Count:
- To reduce latency, costs, and management overhead, aim to use as few tables as possible.
Steps to Design for DynamoDB
Identify Access Patterns
- Review user stories about app activities.
- Document specific use cases.
- Example Access Patterns for an e-commerce app:
- Get a user profile: Retrieve customer contact info.
- Get orders for a user: Fetch customer order history.
- Get a single order and its items: Review items for a given order.
Forecasting Access Patterns
- List required access patterns and expected frequency/response times.
- Helps in determining schema design, primary keys, and indexing.
Schema Design Steps
Define Entities and Relationships
- Create an Entity-Relationship Diagram (ERD).
- Example:
-
User → has many → Orders → has many → Items.
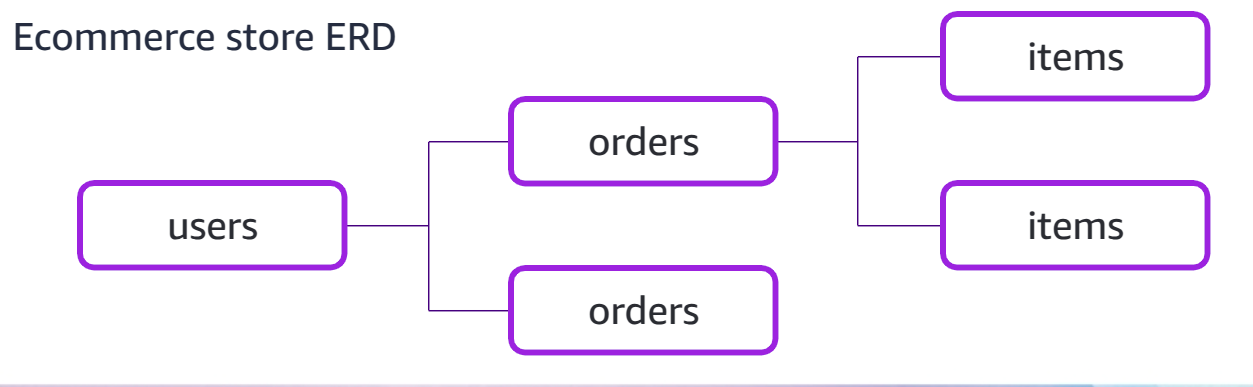
-
- Answer common queries via schema design rather than additional processing.
Define Primary Keys
- Use meaningful Primary Key (PK) and Sort Key (SK) values:
- PK uniquely identifies each entity.
-
SK enables flexible queries within a partition.
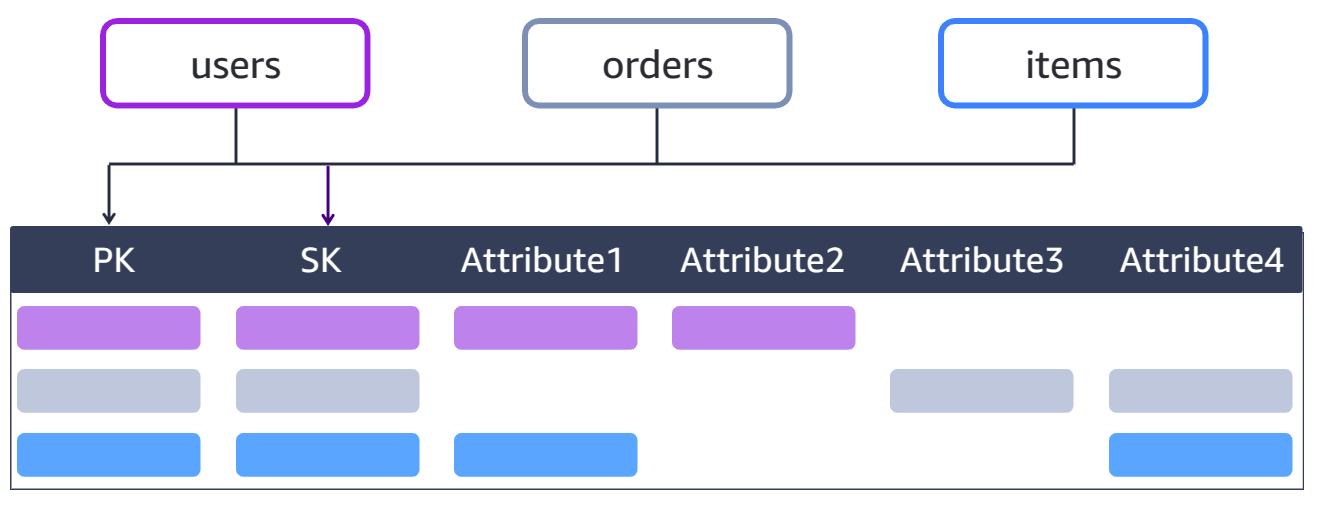
Single Table Design
- Store multiple entity types in a single table (polymorphic design).
- Use generic PK names (e.g.,
PK,SK) to accommodate diverse entities. - Use prefixes (e.g.,
USER#,ORDER#) for entity identification in keys. - Combine different entity types into one table to reduce table count.
Generic PK Naming Example
- PK:
USER#{UserID} -
SK:
ORDER#{OrderID}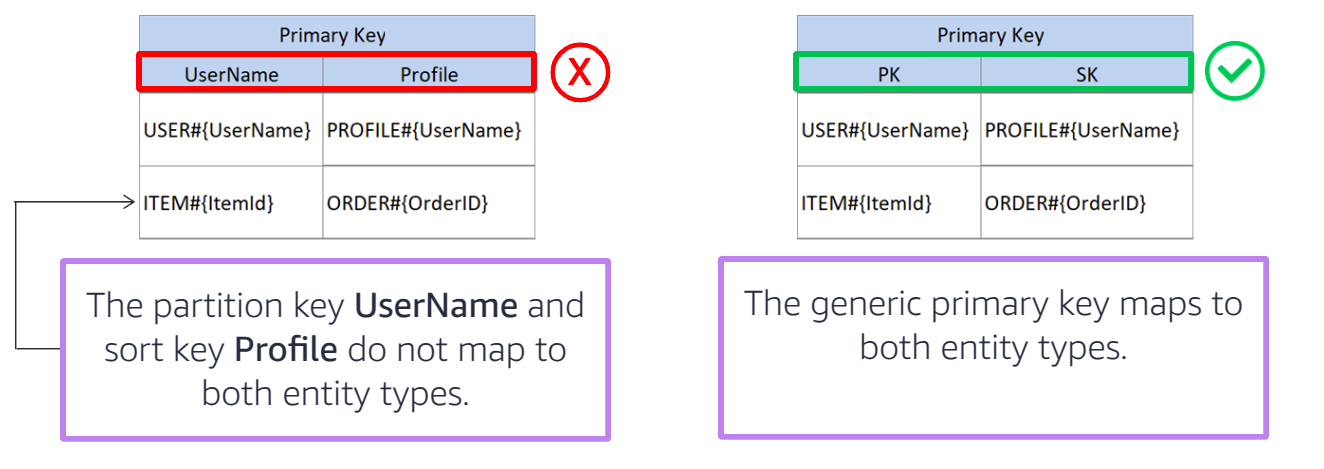
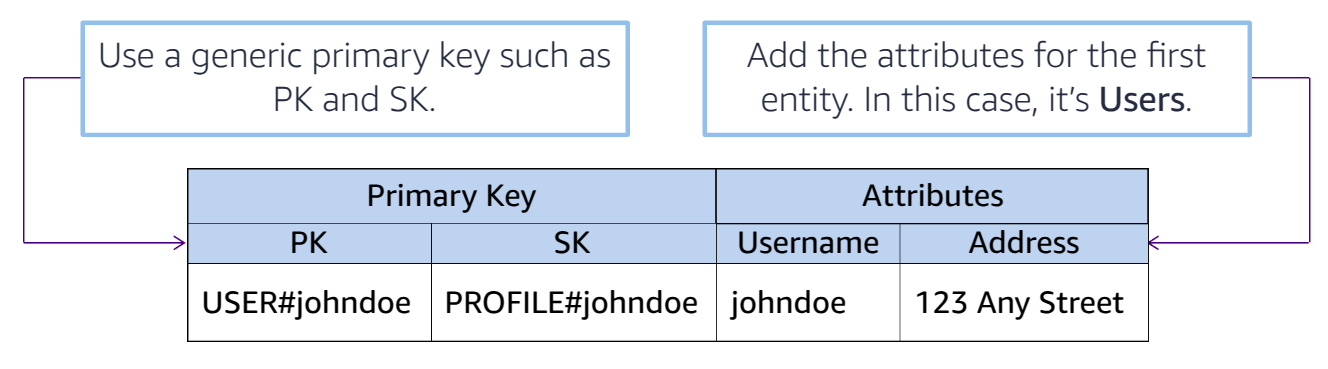


Single Table Design Summary
- Minimize Table Count: Store multiple entities (e.g., users, orders, items) in one table.
- Flexible Querying: Use generic PK and SK names with entity-specific prefixes.
- Entity Diversity: A table can store entities with varying attributes.
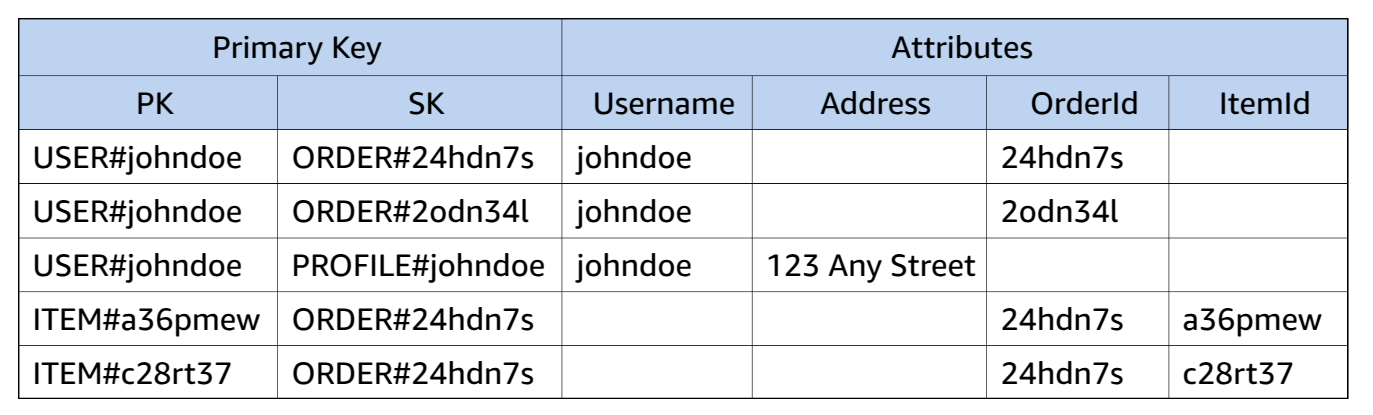
By designing around query patterns and consolidating data into fewer tables, DynamoDB ensures efficient querying, scalability, and cost optimization.
DynamoDB Design Patterns
Required Access Patterns
- Get a User Profile
- Retrieve customer contact information.
- Get Orders for a User
- Fetch the customer’s order history.
- Get a Single Order and Its Order Items
- View details of a specific order, including its items.
Design Plan
- Use composite primary keys:
- Partition Key (PK): Groups related data together.
- Sort Key (SK): Enables efficient querying within a partition.
- Use secondary indexes:
- Optimize for access patterns not efficiently handled by the base table.
Access Pattern Designs
1. Get a User Profile
- PK:
USER#{UserID} - SK:
PROFILE

2. Get Orders for a User
- PK:
USER#{UserID} - SK:
ORDER#{OrderID}

3. Get a Single Order and Its Order Items
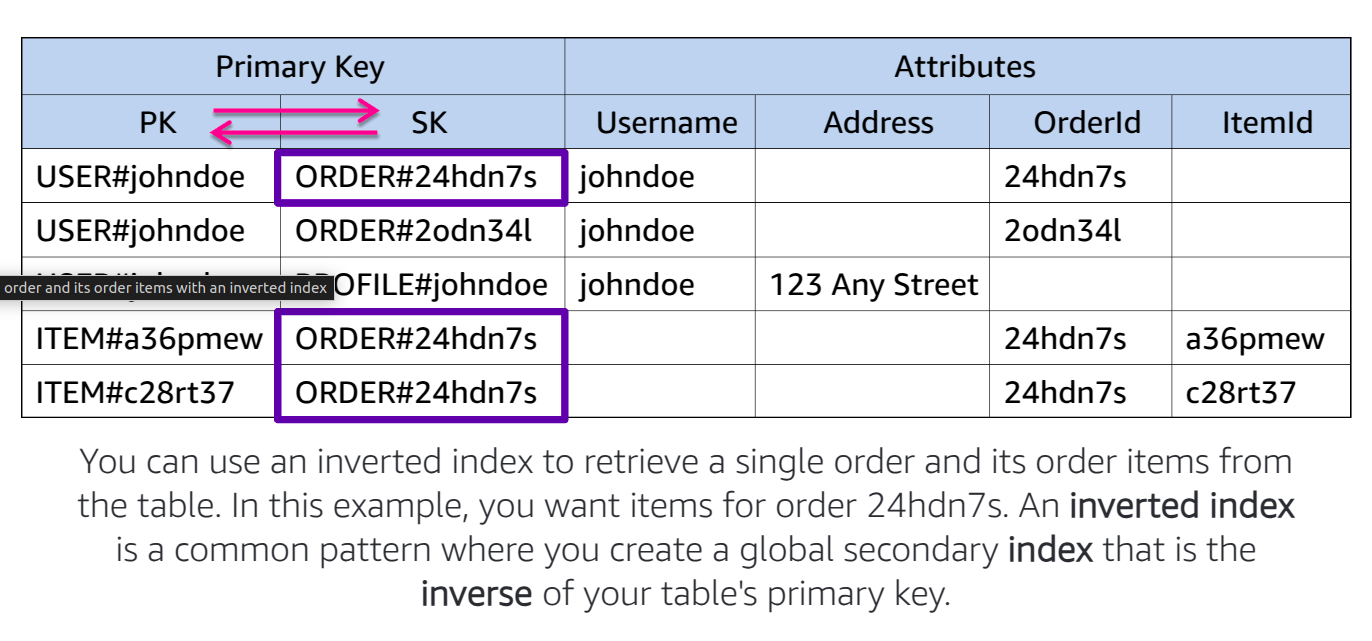
Option 1: Inverted Index (GSI)
- Use a GSI with an inverted key structure to allow querying by order details.
- GSI Partition Key:
ORDER#{OrderID} - GSI Sort Key:
ITEM#{ItemID}
- GSI Partition Key:

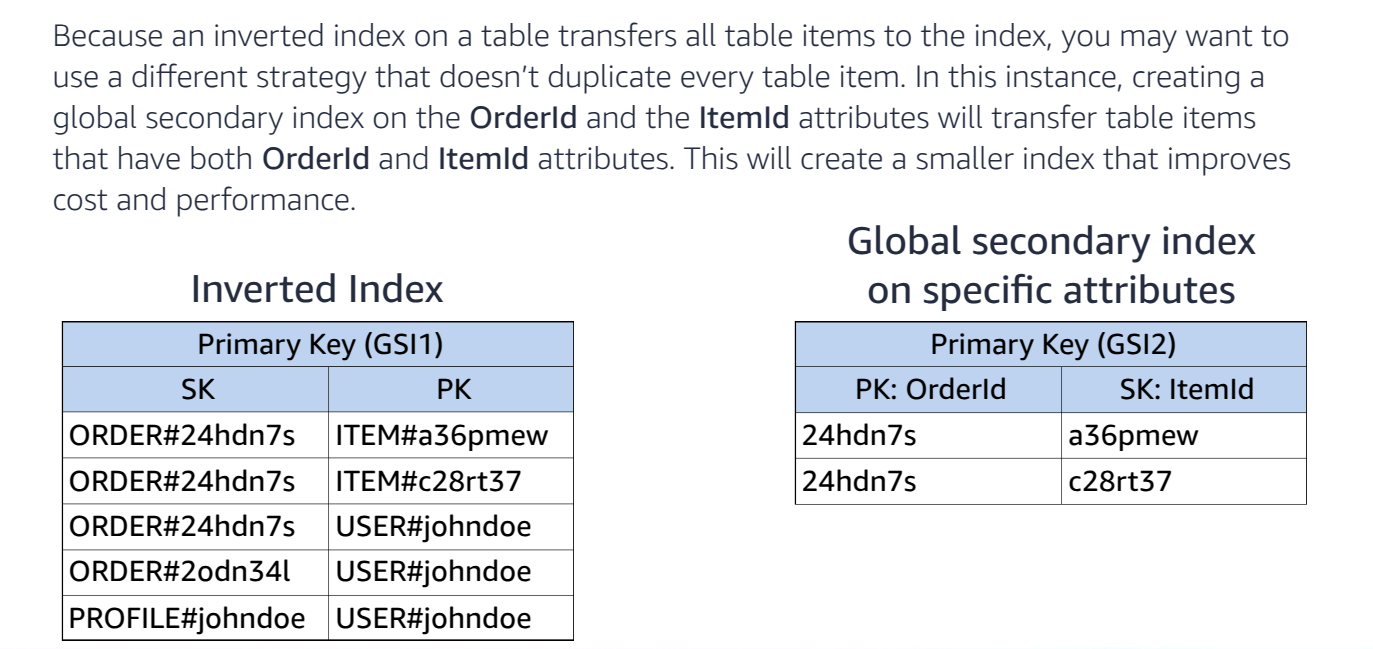
Option 2: Dedicated GSI for Order Items
- Create a new GSI specifically for fetching items related to an order.
- GSI Partition Key:
OrderID - GSI Sort Key:
ItemID
- GSI Partition Key:
Advantages of These Patterns
- Composite Keys: Efficient querying within partitions (e.g., all orders for a user).
- Inverted Index: Flexibility for querying relationships (e.g., order to items).
- Dedicated GSI: Targeted optimization for specific access patterns.
Additional Design Patterns (Hierarchical Data)
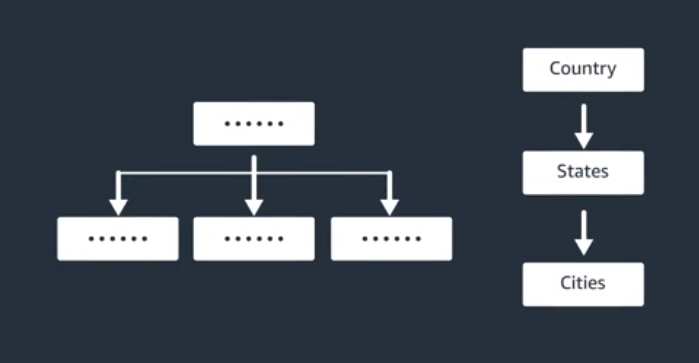
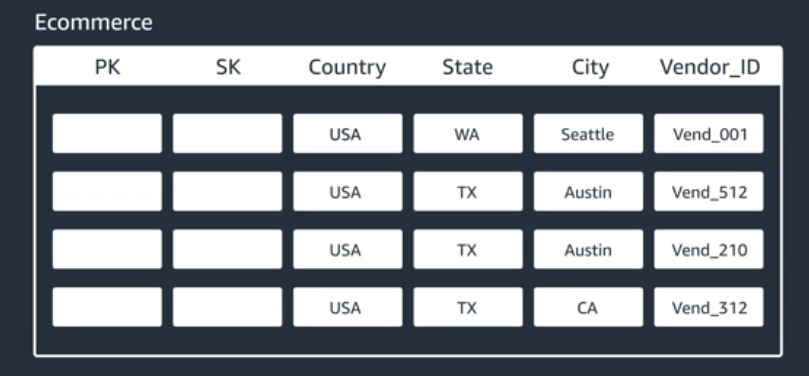
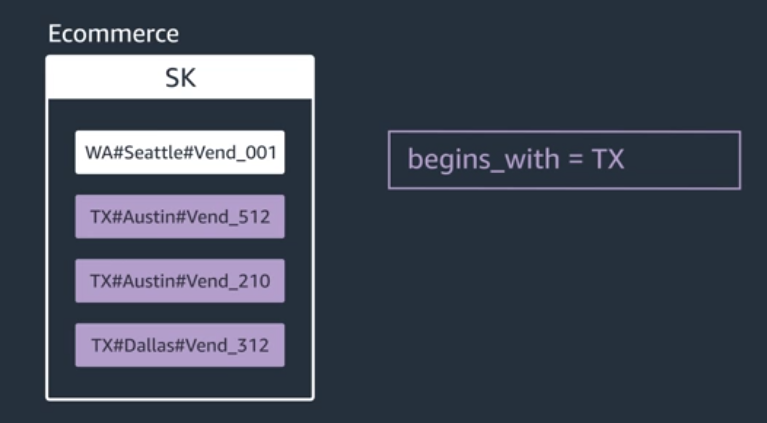
Get All Vendors in Texas
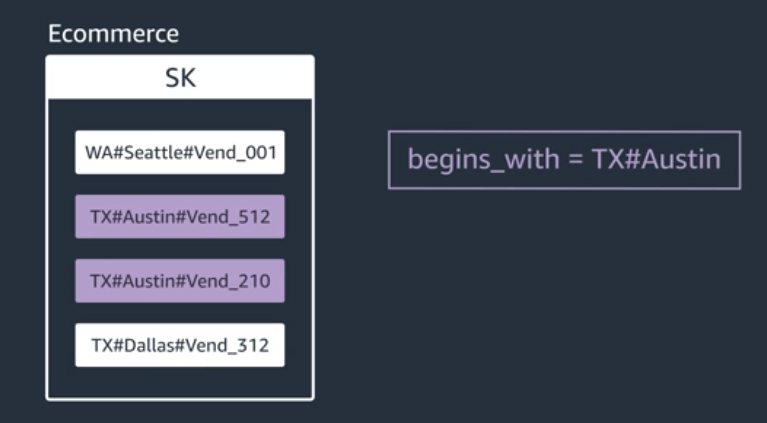
Get All Vendors in Austin, Texas
NoSQL Workbench
Avoid partition keys with low cardinality (e.g., Country) that lead to hot partitions and uneven data distribution.
Data Modeler
Visualizer
Operation Builder